Actualmente, podemos correr FoundationDB desde el mirror oficial de docker publicado por el CI.
https://hub.docker.com/r/foundationdb/foundationdb (hay muchas más cosas interesantes ahí)
docker run -d foundationdb/foundationdbEsto viene con muchas cosas por defecto que nos ahorra tiempo. Luego, si queremos ingresar
docker exec -it fdb bashAhora fdbcli para poder acceder.
Podemos apuntar explícitamente al cluster file dentro del contenedor
fdbcli -C /var/fdb/fdb.clusterVerificar el status y ver si es que viene ya con una base de datos o no. Puede que diga unavaiable.
Nota: el cluster file es la forma en que clientes/servers encuentran el clúster; por defecto vive en /etc/foundationdb/fdb.cluster (en Linux; en el contenedor suele estar en /var/fdb/fdb.cluster). Copiar ese archivo es “cómo” agregas clientes/hosts al clúster, y no se edita a mano salvo para coordinación.
Si no tenemos BD, nos vamos a la documentación:
(Re)creating a database
Installing FoundationDB packages usually creates a new database on the cluster automatically. However, if a cluster does not have a database configured (because the package installation failed to create it, you deleted your data files, or you did not install from the packages, etc.), then you may need to create it manually using the
configure newcommand infdbcliwith the desired redundancy mode and storage engine:configure new single memoryhttps://apple.github.io/foundationdb/administration.html#re-creating-a-database
Con esto creamos una nueva base de datos lista para comenzar a trabajar. Advierte que la instalación de paquetes puede no venir con la base de datos creada y aplica igualmente para el mirror de docker. En todo caso, deberíamos hacerlo pues viene con data que es de prueba.
Para confirmar, no podemos comprobar cuántas bases de datos y tablas hay en fdb, como “select * from table-name” porque Fdb no es una base de datos relacional, por lo que no contiene tablas. Es una OKVS. Todos los datos se encuentran dentro del ámbito único de pares key-value.
Entonces, en fdbcli
getrangekeys "" \xff Esto recorre desde "" hasta “\xff” (cota típica del user keyspace) opcionalmente podemos agregar limit 50.
Nota: al consultar en fdbcli, debe usar comillas dobles ("") en lugar de comillas simples. Las comillas simples no son caracteres especiales.
FoundationDB no es una base que te tira tablas listas ni un admin panel lleno de dashboards. Es pura infraestructura, como un kernel: si no le montas nada encima, no hace mucho más que aceptar operaciones get/set. La gracia es que, desde aquí, puedes decidir qué capa construir arriba, como sistemas distribuidos completos.
Miremos esta matriz de características
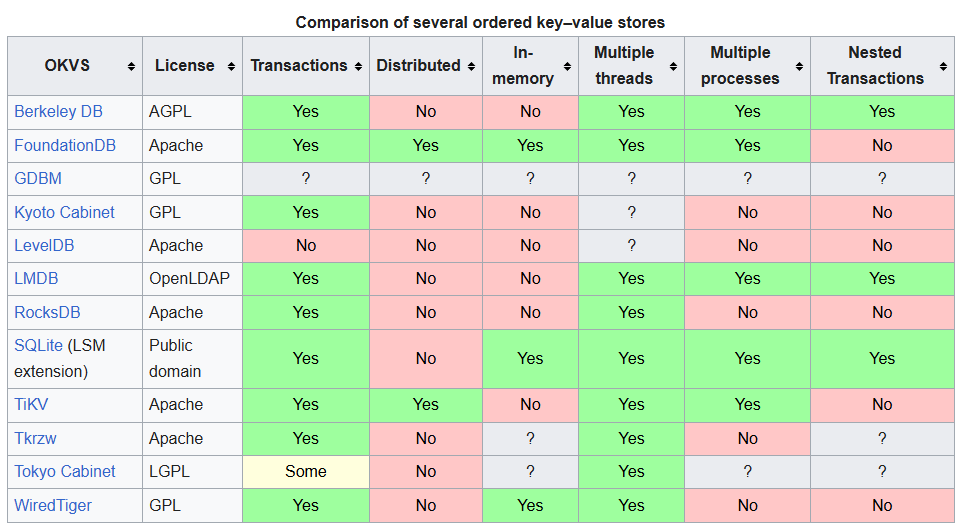
https://en.wikipedia.org/wiki/Ordered_key–value_store
-
OKVS puros (LMDB, RocksDB, LevelDB, Kyoto, BerkeleyDB, WiredTiger, etc.):
→ Son librerías embebibles, pensadas para correr dentro de un solo proceso.
→ Te dan operaciones básicas (
put/get/range) y, en algunos, transacciones locales.→ Ejemplos de uso: LevelDB en Chrome para cache, RocksDB en Kafka Streams, LMDB en OpenLDAP.
-
OKVS distribuidos (FoundationDB, TiKV):
→ No son “solo librerías”: son clusters con consenso, replicación, particionado, failover.
→ Exponen la misma API KV pero garantizan ACID transaccional en todo el clúster.
→ FDB, en particular, tiene un diseño determinista y un transaction log centralizado para serializar commits.
→ TiKV implementa el modelo de Spanner/Percolator (MVCC + Raft).
-
Bases de datos distribuidas más arriba (Cassandra, Spanner, Aurora, Bigtable, etc.):
→ Ya no se presentan como KV crudo, sino como servicios SQL/NoSQL completos.
→ Algunas (Aurora, Postgre, MySQL, Oracle, Percona, uff y tantos más) son RDBMS tradicionales con mecanismos de replicación.
→ Otras (Cassandra, Bigtable, Mongo, Redis) son NoSQL con diferentes consistencias.
→ Aquí FoundationDB se queda más abajo: no te da queries SQL, pero es la capa transaccional sobre la cual podrías montarlo (ejemplo: Record Layer).
-
Infraestructura colateral (BookKeeper, S3/MinIO, ElasticSearch, MeiliSearch):
→ No son DB “core” sino piezas especializadas: log durable, object storage, search engine.
→ Pero todos comparten el mismo patrón: persistencia de datos con diferentes APIs/consistencias.
-
Capas de valor agregado (Record Layer, DeepSeek 3FS, Snowflake FrostDB , Adobe Identity Graph, Ebay NuGraph, sí, todo esto en FDB pero nadie lo dice):
→ Usan un KV transaccional como substrato confiable y montan funcionalidades de alto nivel (SQL, documentos, streams, machine learning datasets).
→ FDB + Record Layer es el ejemplo más claro: Apple construyó CloudKit entero sobre eso.
Y siguen saliendo nuevas tecnologías. TigrisData, Neon, FaRM, FastACS, Yugabyte, Scylladb, TigerBeetle… FoundationDB no es NoSQL, ni NewSQL, es EL kernel de almacenamiento distribuido.